Prologue Ongoing advances in LLMs call for a mathematical model that can analytically model its computability. To do so, it is important to start with a basic model of LLM that captures the core properties, still allowing mathematical tractability. Let’s start with mathematical model for RNNs.
Introduction Consider an RNN network 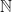


where 



A typical RNN consists of real numbers (weights) that constitute its interior, while the input and the output are passed along digital lines. This is why such networks perform the so-called “analog computing”, where ‘analog’ refers to the real-weight property of them, and ‘computing’ is expressed in a conventional digital, Turing-machine sense. Additionally, out of 

Fig 1: The box with water encoded in the form of Boolean circuits
or neural networks, inside of which analog world exists. The I/O
tape in the bottom of box is where digital readout happens after
the computation is performed.
Definition A language 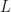
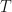




If 

Theorem For functions 
(i) CIRCUIT(F(n)) is subset (or equal to) NET(nF^{2}(n))
(ii)NET(F(n)) is subset (or equal to) CIRCUIT(F^{3}(n))
Proof of (i)
The proof follows from the construction below:

Fig 2: A formal net consists of three networks: input network


and output network 
The formal network NET that can simulate a nonuniform family of circuits CIRCUIT consists of three networks:
(i) 


![\hat{en}[\alpha]](https://s0.wp.com/latex.php?latex=%5Chat%7Ben%7D%5B%5Calpha%5D&bg=ffffff&fg=111111&s=0&c=20201002)
(ii) 

![\hat{en}[c_{n}]0 0 0..](https://s0.wp.com/latex.php?latex=%5Chat%7Ben%7D%5Bc_%7Bn%7D%5D0+0+0..&bg=ffffff&fg=111111&s=0&c=20201002)
(iii) 
![\hat{en}[c_{|\alpha|}]](https://s0.wp.com/latex.php?latex=%5Chat%7Ben%7D%5Bc_%7B%7C%5Calpha%7C%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)

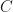
In the above network, only, the middle network is dominating, and its time complexity is given by, 

or,
Remarks
1. The weights of the retrieval network are typically rational numbers, except one weight, which encodes the circuit
2. One might ask what is the meaning of 
Conclusion

- What we have seen is a mathematical model for RNN, simulated using a family of Boolean circuits
- It would be interesting to see next what kind of retrieval network a transformer has. Is it possible to find time complexity of a transformer? The biggest difference between transformer and RNN is the input sequences are processed; temporal in RNN and simultaneously in transformer.
Appendix:
I am confused upon reading some elements related to proving Lemma 3.3.
Source:
Siegelmann, Hava T., and Eduardo D. Sontag. “Analog computation via neural networks.” Theoretical Computer Science 131.2 (1994): 331-360.
